前言
主要来记录一下对RocketMQ的一些认识,包括了比较零散的知识点,主要方便以后回顾。
producer 发送消息到 broker
consumer 从 broker 消费消息
RocketMQ和kafka的区别
Rocket 和 kafka在性能还是有点差距的,kafka在写入TPS在上可以达到百万级,这个是因为kafka中的producer将信息堆起来一起发送,以减少网络IO,但是这个时候如果producer宕机了,会导致信息丢失的,也就是说kafka有点牺牲可靠性来换取性能。
RocketMQ不这么做有以下几点原因:因为堆积的信息会导致内存不足,引发GC。另外就是认为分布式中的单台producer通常也就上万的,不会太高。第三就是producer宕机会造成信息丢失,它保证高可用。
NameServer 无状态
NameServer 本身是无状态的,也就 是说 NameServer 中的 Broker Topic 等状态信息不会持久存储(当然可以通过配置也可以到达持久化)
RocketMQ实现分布式事务
https://m.imooc.com/article/289195?block_id=tuijian_wz
RocketMQ定时(延时)消息
https://blog.csdn.net/qq924862077/article/details/84987179
延时消息的实现还是挺精巧的,首先将延时消息换了一个topic名称进行持久化,这样消费者就无法获取消息,然后有定时任务,会将消息还原到原有的topic信息,这样消费者又可以重新拉取消息了。
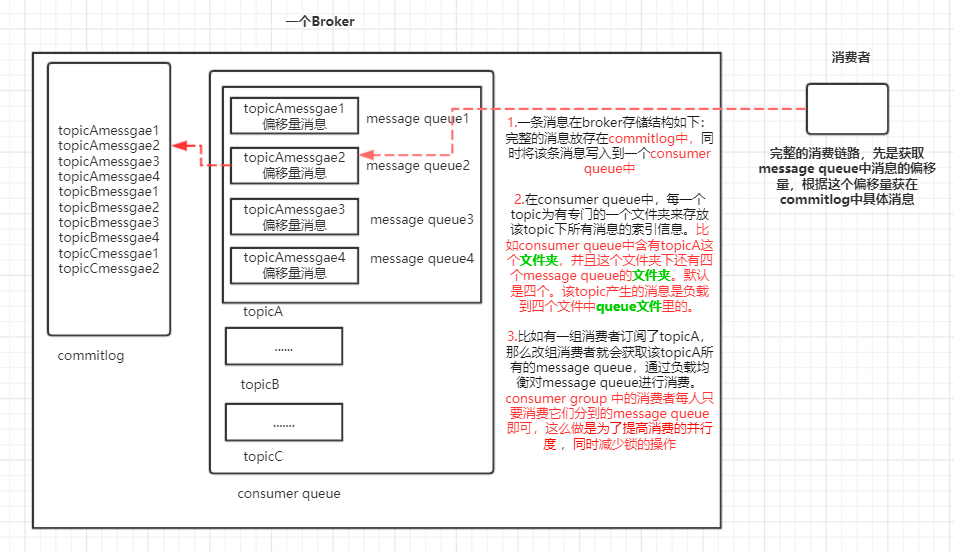
consumer queue中的长度一致吗?
首先偏移量comsuerQueue中是长度一致的,每条消息是不一致的。那ConsumeQueue中当然不会再存储全量消息了,而是存储为定长(20字节,8字节commitlog偏移量+4字节消息长度+8字节tag hashcode),消息消费时,首先根据commitlog offset去commitlog文件组(commitlog每个文件1G,填满了,另外创建一个文件),找到消息的起始位置,然后根据消息长度,读取整条消息。
RocketMQ高可用性
NameServer 都是互相独立的,就算挂了一台也不会影响到使用
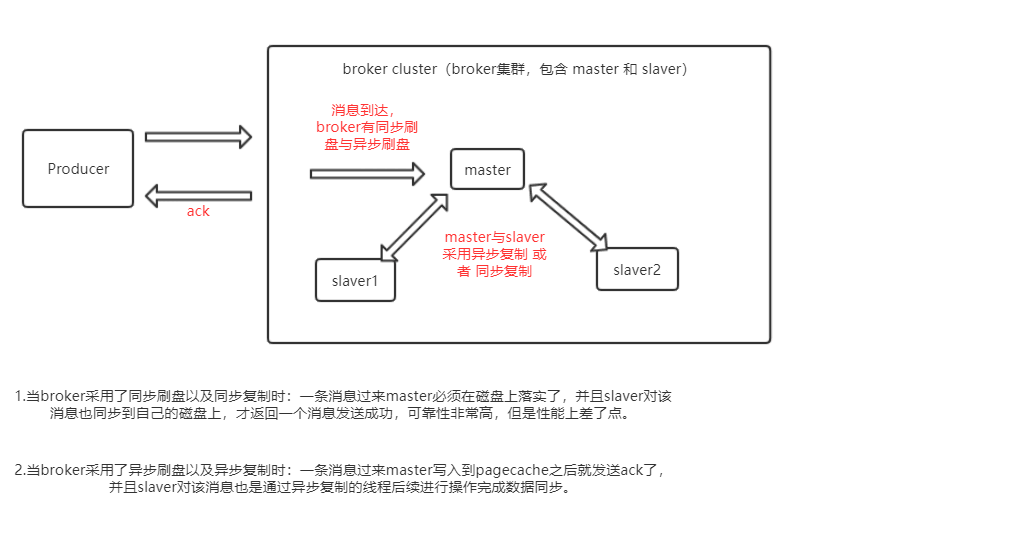
broker采用了主从的架构,每个broker中的master负值读写,只有当master宕机了,slaver才能提供读的功能(但是不能提供写的功能)。
这里与kafka不同的是,kafka采用了ZK来选举,而RocketMQ采用了NameServer是不提供选举的,因此提供了上述的方式来保证高可用性。
kafka在消息写入方面性能比rocketMQ会 有大概10倍的差别,主要是kafka牺牲了一定的可靠性,因为它将消息以堆积的形式进行发送,以此来减少IO的消耗,但是堆积过程中如果发送者宕机了那么消息就丢失了。
而rocketmq提供了同步刷盘与异步刷盘的机制,就是说当消息来的时候,我需要发送一个ack,这个ack如果是在消息落盘之后那就是同步的,表明这个消息是不会被丢失的。如果是直接写入到pagecache中,后面启动另外的线程来刷盘,那就是异步的。
同时在broker中通过同步复制、异步复制的方式来保证高可用性.
RocketMQ广播与集群区别
对于一个consumer group 来说,广播是这个group中每人都会收到消息.如group有三个消费者,总共有9条消息,那么每个消费者各消费9条。如果是集群,会采用queue分配的方式,让三个消费者平均消费9条。
Queue分配策略
Queue分配只有在集群消费模式下使用,广播模式下是没有分配策略的
我们看这个方法AllocateMessageQueueStrategy#allocate(),他有下面几种实现:
- AllocateMessageQueueAveragely:这是默认的分配方式,一个consumer分到在平均的情况下分到连续的queue,待会我们会看看代码
- AllocateMessageQueueAveragelyByCircle: 和上面类似,但是分到的queue不是连续的。比如一共12个Queue,3个consumer,则第一个consumer接收queue1,4,7,9的消息
- AllocateMachineRoomNearby:将queue先按照broker划分几个computer room,不同的consumer只消费某几个broker上的消息
- AllocateMessageQueueByMachineRoom:根据computer room进行hash分配队列
- AllocateMessageQueueByConfig:在用户启动时指定消费哪些Queue的消息
- AllocateMessageQueueConsistentHash:使用一致性hash算法来分配Queue,用户需自定义虚拟节点的数量
主要来看看默认的分配方式:
1 | public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, |
RocketMQ pull 和 push
Push 方式 Server 端接收到消息后,主动把消息推送给 Client 端,实时性高 对于 个提供队列服务的 Server 来说,用 Push 方式主动推送有很多弊 端:首先是加大 Server 端的 作量,进而影响 Server 的性能;其次, Client 处理能力各不相同, Client 的状态不受 Server 控制,如果 Client 不能及时处理 Server 推送过来的消息,会造成各种潜在问题。
Pull 方式是 Client 端循环地从 Server 端拉取消息,主动权在 Client 手里, 自己拉取到 消息后,处理妥当了再接 Pull 方式的问题是循环拉取 消息的间隔不好设定,间隔太短就处在一个 忙等”的状态,浪费资源;每个Pull 的时间间隔太长 Server 端有消息到来时 有可能没有被及时处理
“长轮询”方式通过 Client 端和 Server 端的配合,达到既拥有 Pull 的优点,又能达到保证实时性的目的。简单来讲,就是pull的时候如果broker没有消息时,会hold这个请求一段时间。