前言
前面几篇博客大体上了解了Docker的一些使用。Docker针对于个人开发者开发单机版容器化应用来说,已经足够好用了。
但是在企业应用场景中,很快会因为容器规模增大导致手动操作Docker的方式弊端越来越大。在生产环境中会涉及到健康检查,可用性,负载均衡,服务发现等很多问题。因此,如何批量创建调度和管理成为了亟待解决的首要问题。
Google开源的一个容器编排引擎 Kubernetes,就是为了解决上述问题。这篇我主要来讲一些Kubernetes中常用的组件。方便阐述Kubernetes用k8s代替。

组件概述
每个集群中有一个Master节点对整个集群进行管理;同时系统中存在多个Nodes节点,提供物理资源,这是系统进行资源分配和调度的基础。
在此基础上是Pods和Container,这两个都是虚拟的概念,它是系统分配和部署的最小单元,在一个Node上可以部署多个Pods。一个Pods表示了一个功能或服务,通过对一个或多个Contrainer的整合来实现功能。
最后是Service,它负责对外提供可访问接口,系统中一个Service对应于多个Pod,通过自动化的路由策略对Pod的整合,提供服务拓展,系统容错等功能。下面对上述的组件进行解释。
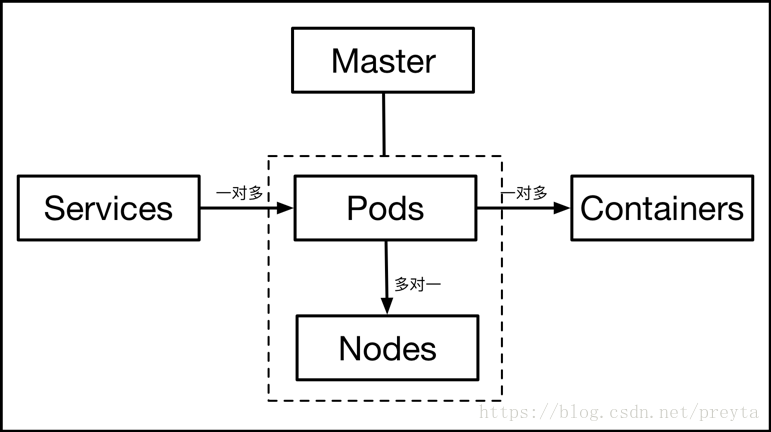
Containers
这里的Containers就是Docker镜像了,这个没什么好说。
Pod
Pod在英文中就是豆荚的意思,每一个在豆荚中的豆就是一个docker容器了,可以说是非常形象了。拿实验室的项目来说,有推荐、搜索、后端业务等功能块,这些功能块可以简单认为就是一个Pod。
如搜索功能需要的docker镜像有Solr和MySQL,也就是说这个pod由两个镜像组成。而推荐需要python一个镜像环境。
Service
也就是说一个Pod实际是提供了某一个功能块的,而多个Pod就形成了一个真正的服务了,这里的服务就是Service了。拿项目来的搜索功能来说,这个Service首先是通过后端业务Pod,后端业务在调用搜索Pod,最后前端显示完成的,这个Service就涉及到了多个Pod的参与。
Master、Node
Master作为控制节点,调度管理整个系统,Node是集群中的工作主机,Node可以是物理主机,也可以是虚拟机。这个在分布式中比较常见,所以不多解释。值得一提的是,每一个Node上可以部署多个Pod。
Replication Controller
简单来说,RC是用来管理Pod的副本的。就拿推荐系统来说,用户使用高峰期时,就需要增到Pod的副本数,从而有效应对大规模的请求。手动去部署多个推荐Pod,存在时间成本,以及部署时集群的负载均衡问题。这些问题可以通过RC来解决。
RC保证在同一时间能够运行指定数量的Pod副本,保证Pod总是可用。如果实际Pod数量比指定的多就结束掉多余的,如果实际数量比指定的少就启动缺少的。当Pod失败、被删除或被终结时,RC会自动创建新的Pod来保证副本数量,所以即使只有一个Pod,也应该使用RC来进行管理。
Deployment
Deployment同样为Kubernetes的一个核心内容,主要职责同样是为了保证pod的数量和健康,90%的功能与Replication Controller完全一样,可以看做新一代的Replication Controller。但是,它又具备了Replication Controller之外的新特性:
- Replication Controller全部功能:Deployment继承了上面描述的Replication Controller全部功能。
- 事件和状态查看:可以查看Deployment的升级详细进度和状态。
- 回滚:当升级pod镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。
- 版本记录: 每一次对Deployment的操作,都能保存下来,给予后续可能的回滚使用。
- 暂停和启动:对于每一次升级,都能够随时暂停和启动。
- 多种升级方案:Recreate:删除所有已存在的pod,重新创建新的; RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用pod数量,最小升级间隔时间等等。