前言
不知道从何说起,不过无论是从技术层面还是市场的需求来看,都需要把学习的重心从solr移到es上,至少现在外面大型的互联网公司都在用es。所以希望以这篇博客来总结一下对solr的学习,也算是给solr这段学习旅程打上半个句号。
回到正题,在前面一篇博客中提到了想要实现自定义的一些查询,可以利用dismax,或者修改源码。dismax的使用在上一篇已经有了简单的介绍,这篇来介绍solr源码的编译和修改。
源码下载
solr的源码可以在Apache的官网找到源码下载,找到想要编译的版本,基于实验的环境,这里我选择的是5.5.2选择图中红框中的源码进行下载。

安装Ant和Ivy
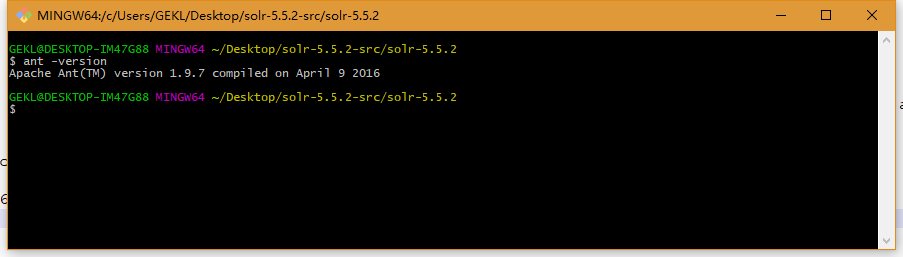
solr是通过ant和ivy来进行管理的,ant用来编译solr项目,ivy是来处理依赖关系的。ant和ivy可以直接去官网下载,下载完ant配置一下环境变量。命令行输入ant -version,下图表示安装成功。
ivy点击这里下载到官网下载后解压开,只要把对应的ivy-2.4.0.jar放到ant目录下的lib中即可。
编译源码
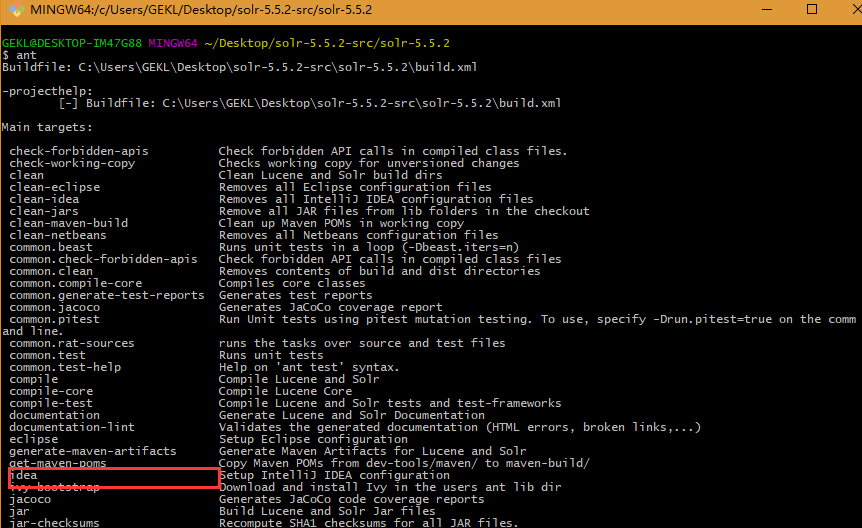
在安装完Ant和Ivy之后,就可以开始编译solr源码了。到我们刚刚下载的solr源码目录下,命令行输入ant,可以看到solr项目可以编译到很多软件去编译,如红框中标出的idea。
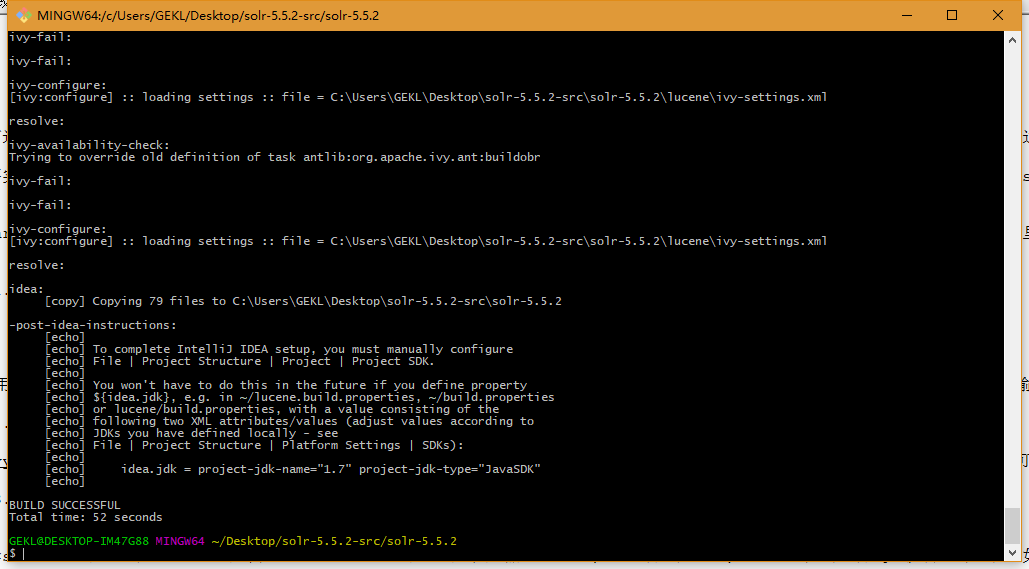
执行ant idea,进行编译。这个编译的过程比较短,直到出现下图表示编译成功了。说明这个项目可以在idea着手编译了。1
ant idea
但是就算现在你把solr的源码改了,solr的服务还不能启动,需要到项目中solr目录下执行ant server,创建solr服务。这个过程执行的时间比较久,大概10分钟左右才成功创建solr服务。这样我们就可以在bin目录下启动我们编译之后的solr服务了。
修改源码
以上的操作都是在为修改源码做铺垫,等上面的工作都完成之后,我们就可以修改源码了。先在ieda中打开我们的项目,在\lucene\core\src\java\org\apache\lucene\search\similarities目录下我们试着添加一个自定义的评分类。
创建一个MyDocScorer类,这个类继承了BM25DocScorer,BM25DocScorer是solr5默认的评分类,我们在这个类的基础上去拓展一下。当然,想要修改,你需要理清lucene的评分逻辑,知道它的评分公式等。
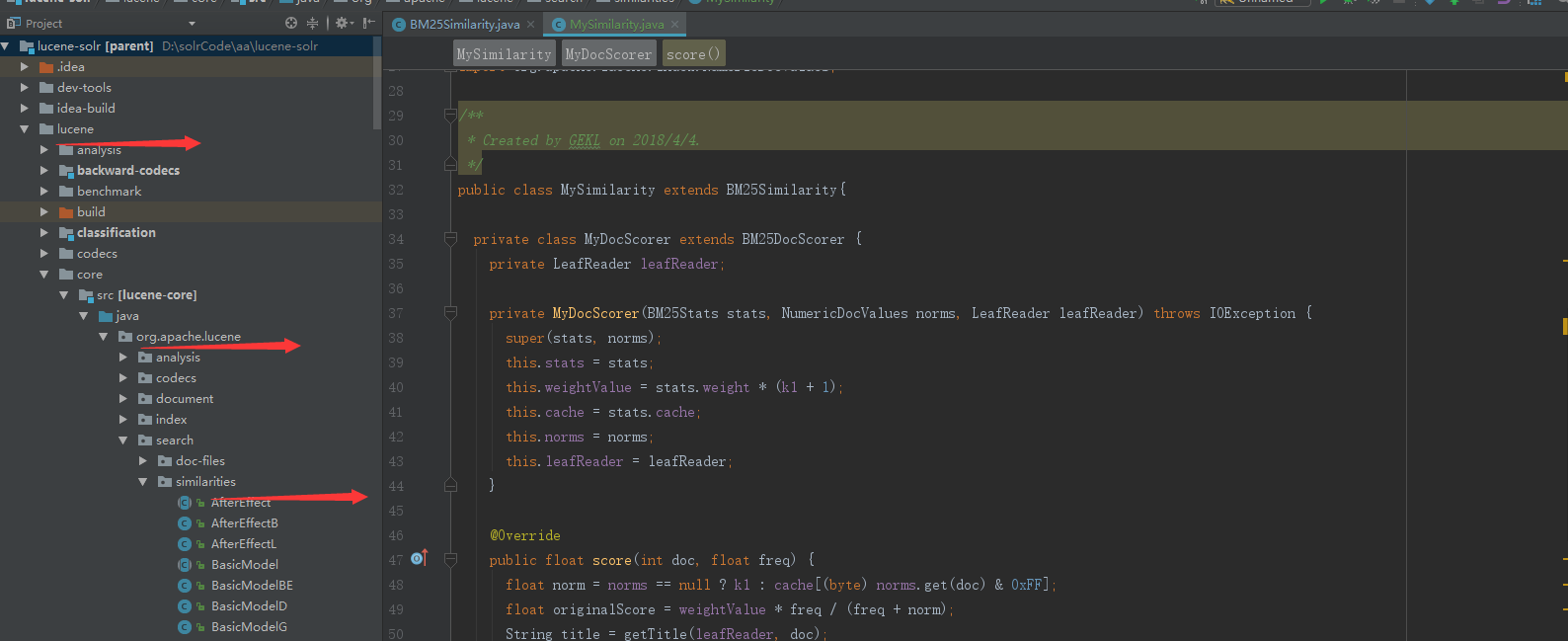
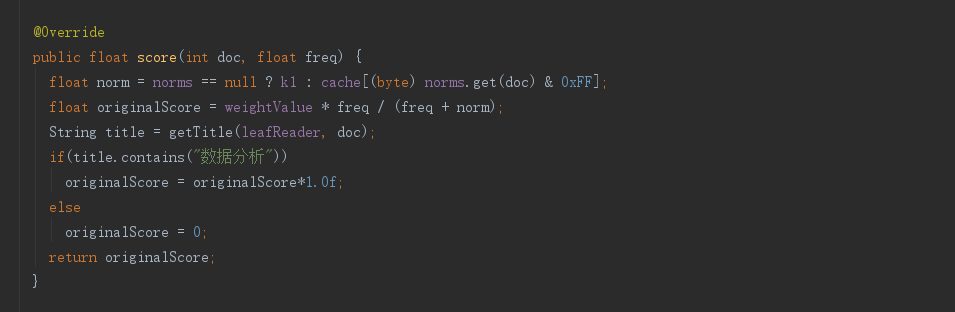
在这里我只是覆盖了BM25DocScorer中的socre方法,只是简单的测试,若文档中的标题中含有”数据分析”这个词,就把该评分*1.0f,就是什么都没干。没含有的返回0分。
完整的代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76package org.apache.lucene.search.similarities;
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.BinaryDocValues;
import org.apache.lucene.index.DocValues;
import org.apache.lucene.index.LeafReader;
import org.apache.lucene.index.LeafReaderContext;
import org.apache.lucene.index.NumericDocValues;
/**
* Created by GEKL on 2018/4/4.
*/
public class MySimilarity extends BM25Similarity{
private class MyDocScorer extends BM25DocScorer {
private LeafReader leafReader;
private MyDocScorer(BM25Stats stats, NumericDocValues norms, LeafReader leafReader) throws IOException {
super(stats, norms);
this.stats = stats;
this.weightValue = stats.weight * (k1 + 1);
this.cache = stats.cache;
this.norms = norms;
this.leafReader = leafReader;
}
@Override
public float score(int doc, float freq) {
float norm = norms == null ? k1 : cache[(byte) norms.get(doc) & 0xFF];
float originalScore = weightValue * freq / (freq + norm);
String title = getTitle(leafReader, doc);
if(title.contains("数据分析"))
originalScore = originalScore*1.0f;
else
originalScore = 0;
return originalScore;
}
public String getTitle(LeafReader reader, int doc) {
try {
BinaryDocValues titleValues = DocValues.getBinary(reader, "title");
String title = titleValues.get(doc).utf8ToString();
return title;
}catch (Exception e) {
System.out.println(e.fillInStackTrace());
return "";
}
}
}
@Override
public SimScorer simScorer(SimWeight stats, LeafReaderContext context) throws IOException {
BM25Stats bm25stats = (BM25Stats) stats;
return new MyDocScorer(bm25stats, context.reader().getNormValues(bm25stats.field),context.reader());
}
}
然后使用Ant进行编译,因为我们就修改了Lucene的Core包里面的东西,所以我们只要执行ant compile-core即可1
ant compile-core
光这样还不行,我们还需要去solr目录下,重新编译创建Solr服务,否则Solr是无法知道我们新加入了那个文件的。1
ant server
想要使用自定义的这个评分类,就到对应的核心配置文件managed-schema下修改

solr源码编译的具体过程就是这样子了,上面只是尝试去修改了一下,本身没什么意义,但是的确可以在对应一些方法中去实现自定义的负责评分机制。
总结
solr的总结就到这了,期间已经开始接触es,分布式的确比solr有很大的优势,所以后面的学习向es前进!