前言
在前面几篇博客上,我对solr的使用以及注意的一些事项有了简单的说明。但是有时候某个具体的业务在配置上是难做到的。举个例子,有这么一份数据,包含了文章的标题、内容、质量(一个整数值)、发布时间等,现在我希望搜索的结果是根据发布时间和文章质量来决定的,即发布时间越早就越靠前、质量越高就越靠前。
目前我所知道的有两种方法,1.利用dismax,在查询的时候提高某个字段的权值。2.修改solr的底层框架Lucene的源码。在这篇我们先来讨论第一种方法。
dismax的使用
dismax可以是在solr的管理界面去配置,也可以在solrconfig.xml中去配置。
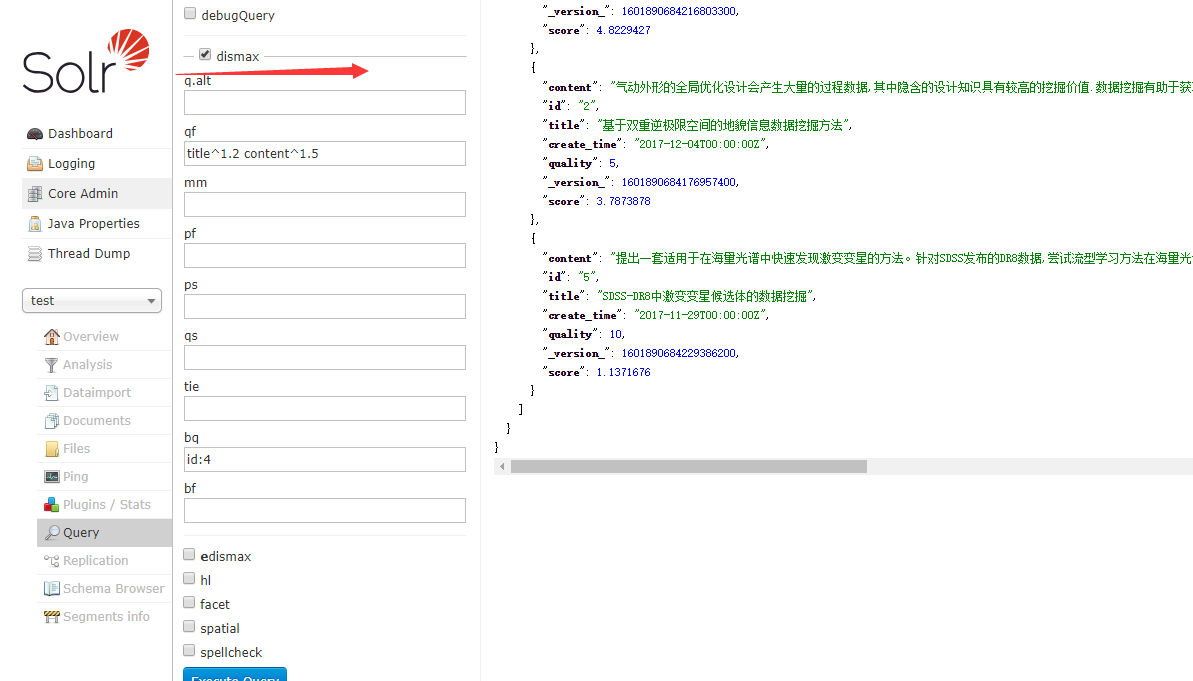
DisMax 查询解析器参数
除了常见的请求参数、突出显示参数和简单的 facet 参数外,DisMax 查询解析器还支持下面描述的参数。与标准查询解析器一样,DisMax 查询解析器允许在 solrconfig. xml 中指定默认参数值,或者在请求中由查询时间值重写。以下部分详细解释这些参数。
q.alt 参数
如果指定,q.alt 参数定义一个查询(默认情况下将使用标准查询解析语法进行解析),当主 q 参数未指定或为空时。q.alt 当您需要一个类似于查询的东西来匹配所有的文档时(不要忘记 &rows=0),q.alt 参数就派上用场了,可以获得收集范围的 faceting 计数。
qf(Query Fields)参数
qf 参数引入了一个字段列表,每个字段都分配了一个 boost 因子来增加或减少该字段在查询中的重要性。例如,下面的查询:1
qf="fieldOne^2.3 fieldTwo fieldThree^0.4"
分配 fieldOne 一个 2.3 的提升, fieldTwo 为默认提升(因为没有 boost 因素被指定),并且 fieldThree 提高 0.4。这些 boost 因素使 fieldOne 中的匹配比 fieldTwo 的匹配更加重要,它比 fieldThree 中的匹配更为重要。
pf(Phrase Fields)参数
一旦使用 fq 和 qf 参数确定了匹配文档的列表,就可以使用 pf 参数“boost”文档的得分,因为 q 参数中的所有项都出现在非常接近的情况下。该格式与 qf 参数所使用的格式相同:当从整个 q 参数中进行短语查询时,字段列表和“boosts”将与每个字段相关联。
bq(Boost Query)参数
bq 参数指定一个附加的可选查询子句,将添加到用户的主要查询中以影响 score。例如,如果您想为id为5的文档添加相关性 boost:1
bq=id:5
bf(Boost Functions)参数
bf 参数指定将用于构造 FunctionQueries 的函数(具有可选的 boosts),该函数将作为将影响 score 的可选子句添加到用户的主查询中。可以使用由 Solr 本地支持的任何函数,以及 boost 值。例如:1
sum(sqrt(log(ms(createTime))))
上面的函数就是把创建时间的字段考虑到排序中,具体的函数说明可以查看这里 函数查看。
solrconfig中去配置
和在solr管理界面差不多,只要在solrconfig.xml添加上自定义的requestHandler。如下所示: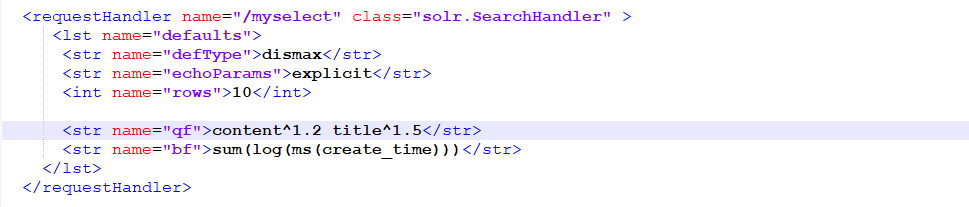
浏览器输入:http://localhost:8983/solr/test/myselect?q=数据挖掘&wt=json&indent=true,使用自定义的这个myselect,效果和在管理界面中配置是一样的。