前言
在上一篇博客中,我们已经完成了Solr的搭建和简单的查询,今天我们来讲讲Solr的中文分词hanLp,以及它的应用场景。先来看一下,我们在百度上搜索hanlp时,推荐给我们的网页要么是内容中出现过hanlp这个词,要么是标题是含有hanlp的。
试想一下,如果让你实现这个功能块,你会怎么做呢?那不是很简单嘛!只要一篇篇的文章,去查询一下标题和内容是否出现过hanLp就好了嘛!的确这是一种方法,但在数据量过大时,这样的全文匹配的效率是非常低的。在Solr中,采用反向索引来解决上面带来的效率问题。
反向索引
在讲反向索引之前,先来看看平常的索引是怎么样的。假设这里有两篇文档数据格式如下
| docId | content |
|---|---|
| 1 | this is a good book |
| 2 | this book is about hanLp |
给这两篇建立索引的时候,会去掉标点符号,还有一些没有特殊意义的如”a”,”the”,”is”这些词去掉。那么正常的索引就是
| docId | content |
|---|---|
| 1 | [this],[good],[book] |
| 2 | [this],[book],[about],[hanlp] |
那么在这个正向索引的基础上,我们通过一篇篇的遍历会找到hanlp这个词在docId为2的文章出现,于是把这篇返回。那么反向索引是怎么样呢?正常索引是根据docId找到词,而反向索引则是用词来找docId。
| term | docId |
|---|---|
| this | [1],[2] |
| book | [1],[2] |
| good | [1] |
| about | [2] |
| hanlp | [2] |
那么在这个反向索引上,通过找到hanlp这个词,把对应的docId返回回去,这样就避免一篇篇文章的全文档的扫描了,查询速度就这样变快了。那么问题来了,在上面案例中,使用的是英文,我们只要将词一个个切开了即可。但是因为是中文的原因,将一个词语拆成两个字会将语意破坏掉。
比如说,我要搜索“大数据的文章”的相关内容,按照上面的方式,会把含有像”大”、”的” 这些个无关紧要词的文章也返回回来,导致搜索的效果很差。所以在中文分词和英文的分词是有很大的区别的。
hanLp安装
在Solr中通常使用的有IK分词、hanLp分词等,本案例使用的是hanLp分词。首先下载 hanlp-portable.jar 和 hanlp-lucene-plugin.jar, 点击下载,把下载好的jar放到solr-webapp\webapp\WEB-INF\lib中即可。
光有这两个插件其实是不够的,上面提供的分词器是Portable版的,比较简陋,所以还需要 HanLP 的核心数据集,可以去https://github.com/hankcs/HanLP/releases 下载。以及配置文件hanlp.properties。
在solr-webapp\webapp\WEB-INF下新建一个目录 classes,然后将刚才下载的配置文件hanlp.properties放进去,再在 classes 目录下新建一个文件夹 hanlp,然后将下载的数据集解压出来的 data 文件夹放到 hanlp 目录下面。
最后的目录结构像这样
1 | WEB-INF |
修改配置文件 hanlp.properties,只需要把root的值修改一下即可,默认如下:1
2#Windows用户请注意,路径分隔符统一使用/
root=D:/JavaProjects/HanLP/
比如,我要改成root=D:/solr/solr-5.5.2/solr-5.5.2/server/solr-webapp/webapp/classes/hanlp/
下面我们到managed-schema中进行配置,把需要进行分词的field中的type类型改成text_hanlp即可。因为text_hanlp不是solr自带的,所以我们还要在这个配置文件申明。1
<field name="word" type="text_hanlp" indexed="true" stored="true" required="false" multiValued="false" />
1 | <fieldType name="text_hanlp" class="solr.TextField"> |
注意一点的是,因为在上一篇博客中我们配置了一个默认字段,默认字段的type是String,如果我们查询的时候,没有指定域时那么查询词的类型不是text_hanlp而是string,搜索词是不会被分词的,所以需要在默认字段中也要把type设置为text_hanlp1
<field name="defaultField" type="text_hanlp" indexed="true" stored="false" required="false" multiValued="true" />
接下来只要重启一下solr服务,并且重新dataimport一下,因为我们的索引方式已经变化了。
看一下效果分词之后的效果,就算我们的word中有没有“数据挖掘”这个完整的词语,但是因为分词的原因,word中的“数据挖掘人工智能”,被分成了”数据挖掘”,“人工智能”,把这两个词进行反向索引,所以我们在搜索”数据挖掘”的 时候,对应的记录也会被找到。
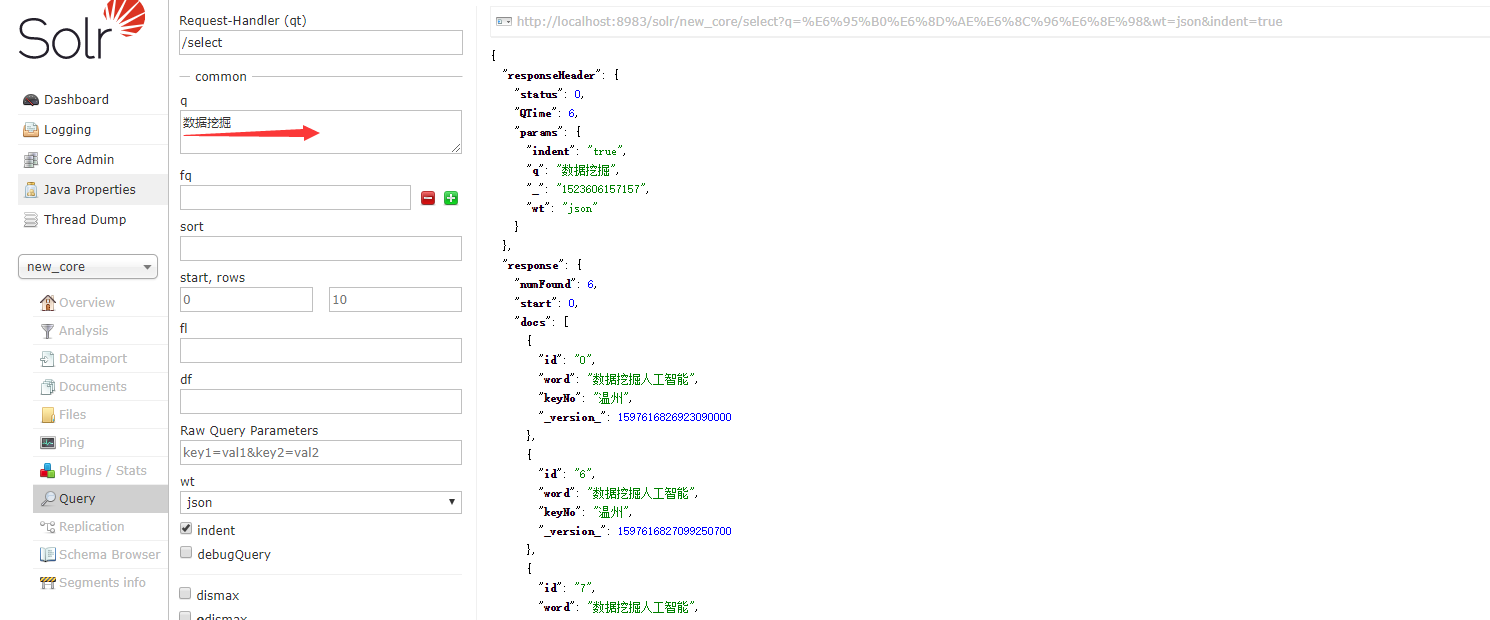
如果你想看一下,你的中文都被分成了什么字段,你可以在Solr界面中的analysis查看
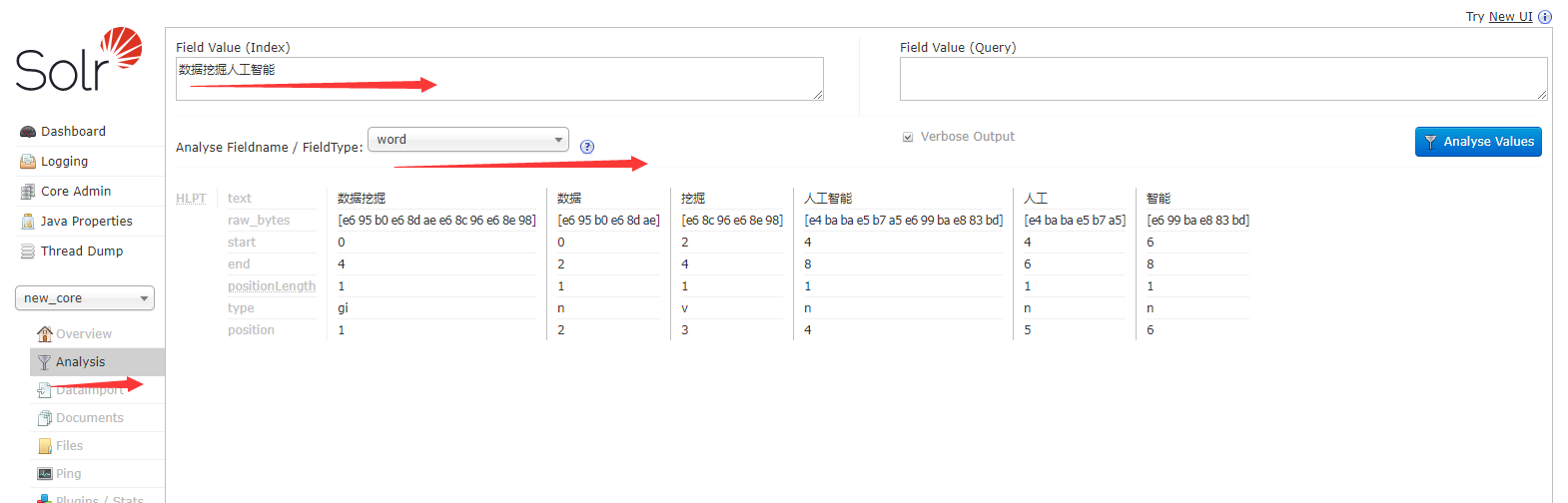
从上图我们可以知道,搜索”数据”、”挖掘”也都是能找得到对应的记录的。